 Track the T
Track the TRAMPART
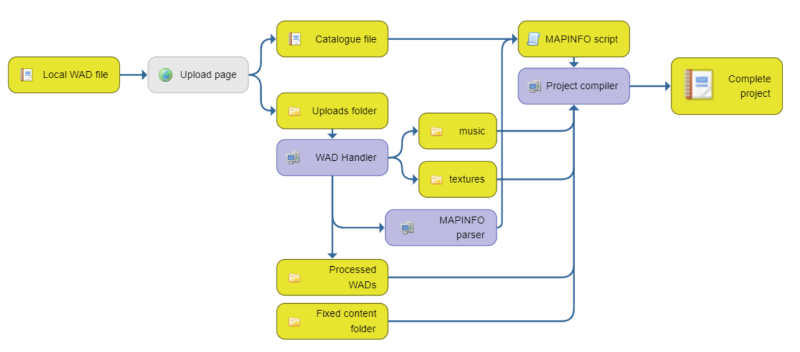
Originally released in 1993, DOOM by id Software had a colossal impact on the growing computer game industry with its innovative 3D technology. Since the release of the source code in the late 90s, the fan community has continuously extended the base engine's capabilities, collaborating to invent new renderers, features and a C#-based OOP language "ZScript". In the modern fan community, it's common to run community projects where maps, code and other assets are contributed by many individual authors - and these projects have historically been difficult to manage, keeping track of constant updates from many sides.
RAMPART is a continuous integration environment I invented specifically for Doom community projects. It's comprised of a PHP frontend for submitting and updating individual .WAD data files, and a backend that takes the submitted data and compiles it all into a complete project - flagging or automatically handling conflicts as appropriate. Because the Doom file formats have their roots in MS-DOS and didn't have the luxury of being expressed in comfortable JSON or YAML, writing this integrator involved the interesting challenge of dealing with data at the byte level.
I run a yearly project RAMP to help get people into making maps or games for the GZDoom source port of the engine, and RAMPART has evolved over the last several years to support its needs. It's beginning to be adopted by others in the Doom community as well to handle the infamously difficult task of herding community projects together.
RAMPART is open-source on GitHub.
RAMPART is a continuous integration environment I invented specifically for Doom community projects. It's comprised of a PHP frontend for submitting and updating individual .WAD data files, and a backend that takes the submitted data and compiles it all into a complete project - flagging or automatically handling conflicts as appropriate. Because the Doom file formats have their roots in MS-DOS and didn't have the luxury of being expressed in comfortable JSON or YAML, writing this integrator involved the interesting challenge of dealing with data at the byte level.
I run a yearly project RAMP to help get people into making maps or games for the GZDoom source port of the engine, and RAMPART has evolved over the last several years to support its needs. It's beginning to be adopted by others in the Doom community as well to handle the infamously difficult task of herding community projects together.
RAMPART is open-source on GitHub.
The Making of RAMP

After running the first year of the Doom community project RAMP, I put this small book together journalling the twists and turns of making the project, and how the design and mechanics of RAMPART were influenced by the audience's needs. Some of the details in the book are quite heavy on Doom-specific scripting languages, but the concepts of designing and developing software to suit users are much the same as in any development cycle.
The Making of RAMP
The Making of RAMP
ROSITA
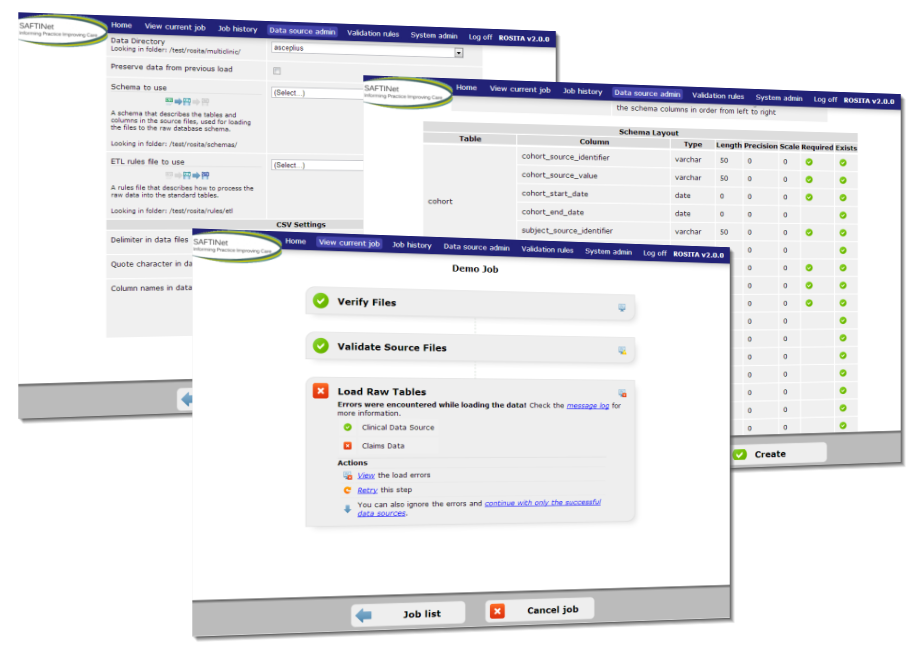
ROSITA is a system for validating electronic medical record (EMR) data and processing it into the OMOP standard. It was written for the University of Colorado Denver's SAFTINet project, which involves a network of partners publishing data through their own ROSITA instances into a combined searchable network of OMOP data. Each partner may have wildly different data formats, so ROSITA is configurable to accept custom database schemas and rule lists to load, de-duplicate and de-identify data.
My initial role in the ROSITA project was in experimenting with database batch loading techniques using JAXB and STAX in order to load very large amounts of XML data (30GB per file) in an acceptable time frame. Afterwards, the scope of the project was expanded to include a frontend, and I implemented a web application that communicated with a command line script to handle the transformation and load processes, along with a rich jQuery-based UI to report on progress through the workflow.
ROSITA is owned jointly by Deloitte and the University of Colorado Denver.
My initial role in the ROSITA project was in experimenting with database batch loading techniques using JAXB and STAX in order to load very large amounts of XML data (30GB per file) in an acceptable time frame. Afterwards, the scope of the project was expanded to include a frontend, and I implemented a web application that communicated with a command line script to handle the transformation and load processes, along with a rich jQuery-based UI to report on progress through the workflow.
ROSITA is owned jointly by Deloitte and the University of Colorado Denver.
teamouse.net
teamouse.net is a site I put together to showcase the work I've done both professionally and personally over the last few years - music, coding and whatever else comes to mind.
The site runs from home on a Raspberry Pi minicomputer, using the apache2 web server with a MySQL database. It collects information from several of my accounts elsewhere on the Internet through scripts running in bash and Python, run regularly through a cron job.
The site runs from home on a Raspberry Pi minicomputer, using the apache2 web server with a MySQL database. It collects information from several of my accounts elsewhere on the Internet through scripts running in bash and Python, run regularly through a cron job.
Track the T
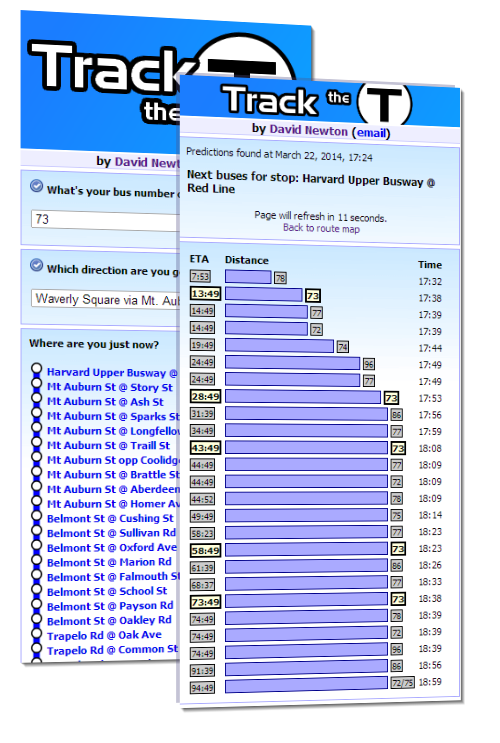
Track the T is a PHP-based web application that uses XML data from NextBus to provide visitors with up-to-the-minute bus and subway arrival time predictions across the MBTA network. It was written as an experiment when the MBTA released an XML feed for bus arrival times in 2009, and became popular enough to get converted to its own site once the realtime feed was made public, having the advantage of being one of the few purely web-based applications in a market of specific phone apps.
Currently it has a wide fan following on Facebook and provides bus information for six thousand unique visitors each weekday.
Currently it has a wide fan following on Facebook and provides bus information for six thousand unique visitors each weekday.
tranSMART
I've worked on several customizations of the translational research application tranSMART, as well as contributing code to the base open source project. Clients whose projects I worked on included Pfizer, Sanofi and Biogen Idec, and I developed features such as:
- A unified search across subject-level and study-level data
- Search within GWAS and eQTL data - being able to filter data by gene, chromosomal position or region
- The ability to attach arbitrary files to studies or analyses
- A procedure for uploading new analysis data in delimited list form, requiring validation of the data and interaction with the existing backend scripts to perform ETL
- The development of a SAS connector so that tranSMART data could be leveraged in SAS scripts - a new challenge, especially as this also involved gaining familiarity with the existing R connector
SHRINE Management Server
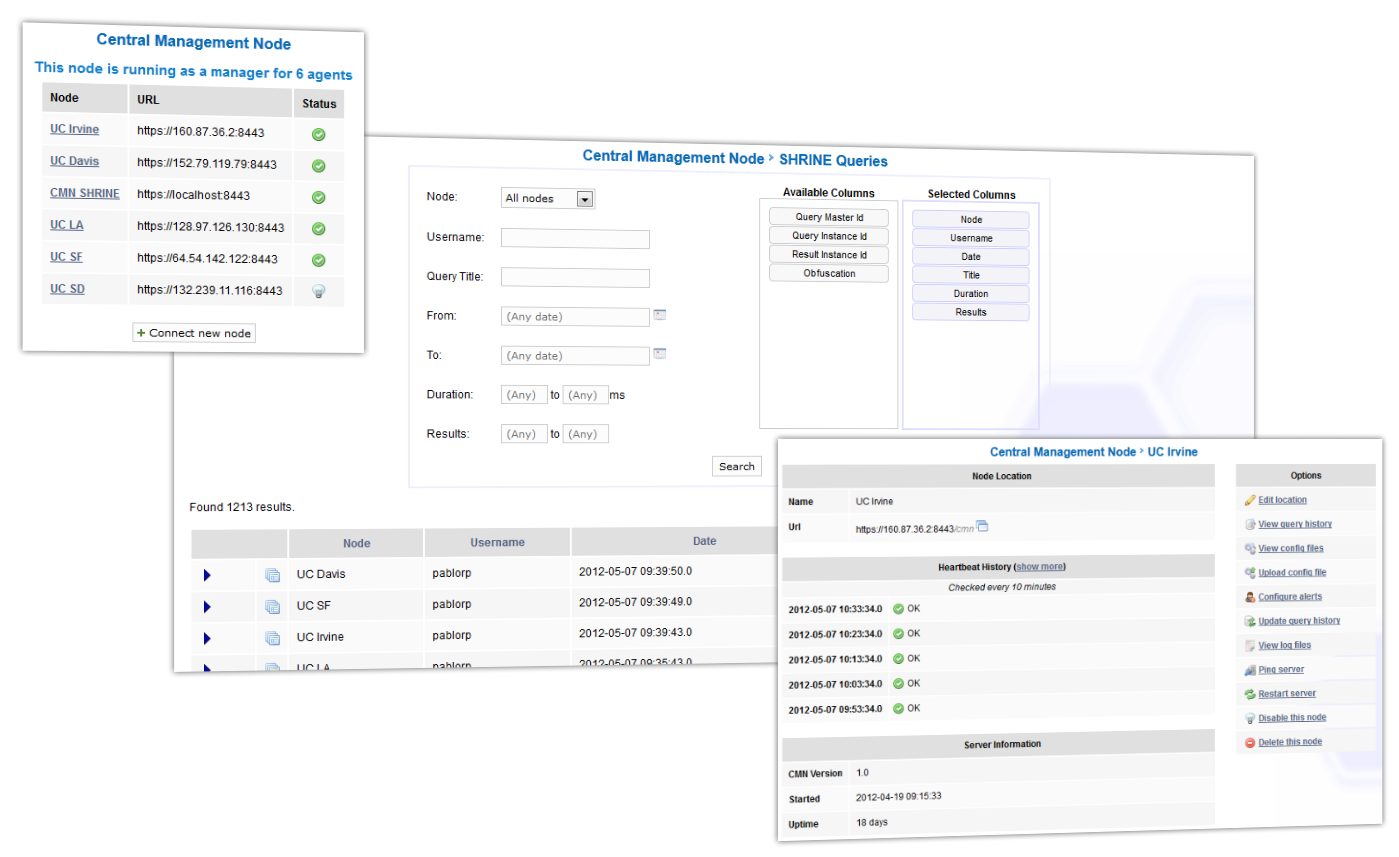
The SHRINE Management Server is a Grails application for monitoring and managing nodes in an i2b2 SHRINE network. SHRINE was developed at Harvard University, and is a system that allows the linkage of multiple i2b2 instances across different sites.
I was tasked with designing and developing the tool during an installation of a SHRINE network for five sites at the University of California. These networks are notoriously challenging to set up due to the large number of moving parts in them - opening the correct firewall ports, communicating between database/application/proxy servers within each site, routing traffic correctly across sites and ensuring that each site has the correct SSL key information.
The SMS assists with this process by providing a Tomcat Grails application as a frontend for monitoring the status of nodes in a network - this can involve testing whether each node can be reached over HTTP or HTTPS, if it responds to ping and if the i2b2 instance is responding correctly. Alerts can be configured so that IT staff are notified if a node hasn't responded for a given time. It also allows a user to push new configuration files out to nodes from one central location, check web server log files and remotely restart nodes.
The Shrine Management Server technology is owned by Deloitte.
I was tasked with designing and developing the tool during an installation of a SHRINE network for five sites at the University of California. These networks are notoriously challenging to set up due to the large number of moving parts in them - opening the correct firewall ports, communicating between database/application/proxy servers within each site, routing traffic correctly across sites and ensuring that each site has the correct SSL key information.
The SMS assists with this process by providing a Tomcat Grails application as a frontend for monitoring the status of nodes in a network - this can involve testing whether each node can be reached over HTTP or HTTPS, if it responds to ping and if the i2b2 instance is responding correctly. Alerts can be configured so that IT staff are notified if a node hasn't responded for a given time. It also allows a user to push new configuration files out to nodes from one central location, check web server log files and remotely restart nodes.
The Shrine Management Server technology is owned by Deloitte.
Crystal Towers 2

I've created numerous large and small games in the visual programming environment Clickteam Fusion, and have written a number of tutorials aimed at users of the software on how to implement basic physics and to communicate with online databases.
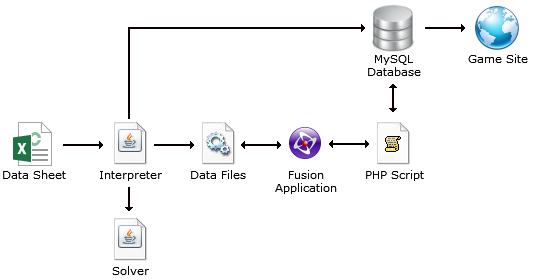
Crystal Towers 2 was my most ambitious project. Many Fusion applications are entirely self-contained, but the complex nature of the game and its data required several other elements to form a development pipeline and tools to support them. Data for the game's mechanics - prerequisites for the player to enter new areas, the chance of finding randomly-generated treasure items, and so on - was organized in a spreadsheet, with a command line tool written to translate the sheet into data files that could be interpreted by the game. Because of the game's non-linearity, it was also difficult to manually keep track of a player's options and potential objectives at any point - therefore, on each export, the data was fed to a state-tree solver to verify that the game mechanics still resulted in multiple possible routes to completion.
Players of the game also have the option to share their progress by uploading their data to the game's site - this is achieved by the game sending POST HTTP requests to PHP scripts that manage the data and store it in a MySQL database. The upload script also generates a "news feed" that gets posted to the site's front page, by checking for important events since the last time the player uploaded their save file.
 The game was featured in the IndieGala Weekly Bundle in April 2014, and has been among the most-viewed titles on the independent game distribution site Desura, reaching the #1 spot for a day on Monday 21st April 2014!
The game was featured in the IndieGala Weekly Bundle in April 2014, and has been among the most-viewed titles on the independent game distribution site Desura, reaching the #1 spot for a day on Monday 21st April 2014!
Crystal Towers 2 was my most ambitious project. Many Fusion applications are entirely self-contained, but the complex nature of the game and its data required several other elements to form a development pipeline and tools to support them. Data for the game's mechanics - prerequisites for the player to enter new areas, the chance of finding randomly-generated treasure items, and so on - was organized in a spreadsheet, with a command line tool written to translate the sheet into data files that could be interpreted by the game. Because of the game's non-linearity, it was also difficult to manually keep track of a player's options and potential objectives at any point - therefore, on each export, the data was fed to a state-tree solver to verify that the game mechanics still resulted in multiple possible routes to completion.
Players of the game also have the option to share their progress by uploading their data to the game's site - this is achieved by the game sending POST HTTP requests to PHP scripts that manage the data and store it in a MySQL database. The upload script also generates a "news feed" that gets posted to the site's front page, by checking for important events since the last time the player uploaded their save file.
BLIMS/SampleTrust
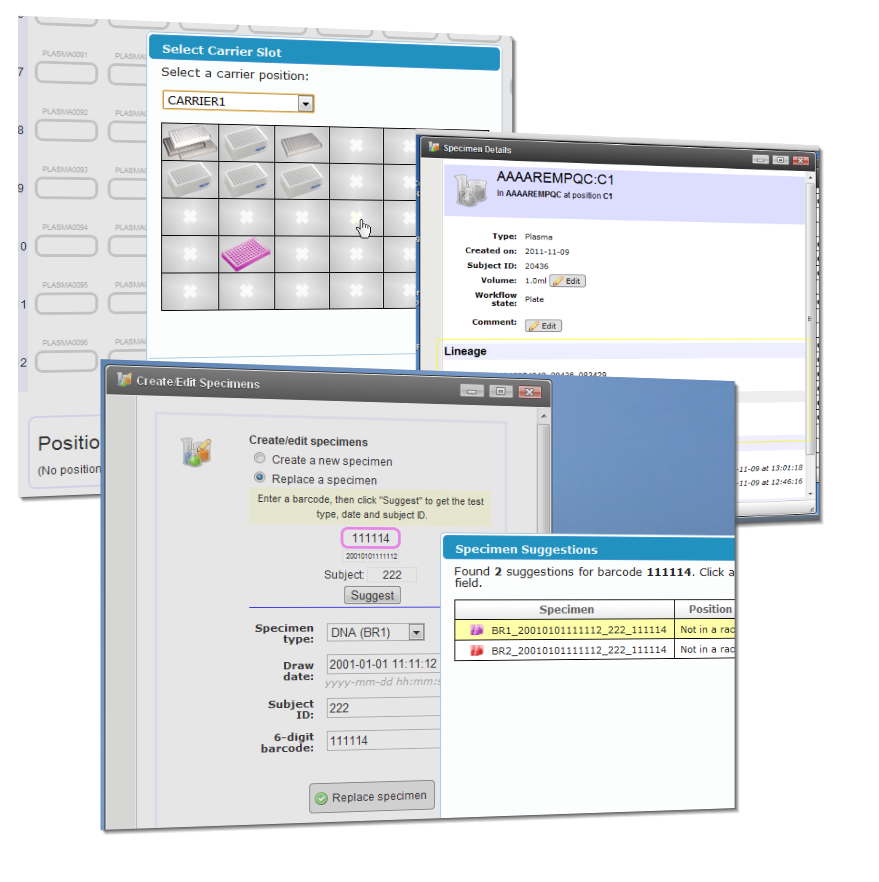
BLIMS (Biolaboratory Inventory Management System), or SampleTrust, is a project I designed and developed for UMass to keep track of blood samples as they progressed through a complex physical workflow, being duplicated, separated from tubes on to plates, sent and received back from a warehouse and delivered to customers.
The application was written in the Java/Groovy-based Grails framework, and was designed to resemble a Windows desktop with a set of different tools available to technicians, a requirement that provided unique user interface challenges. These included facilities for searching for specimens by various properties, for entering layouts of physical tube racks (with the requirement that the form had to elegantly cope with the input from a handheld barcode scanner) and for recording procedures performed on tubes such as freezing, thawing and aliquotting. Data from lab equipment was also captured from files through Apache Camel.
The system had to interact with the open source biobanking system caTissue, which presented further challenges as at the time its developer API was inadequate to cover the needs of the project (being generally awkward to use and very slow at tasks like creating multiple samples at one time - a vital feature when the workflow involved separating samples into 96-well plates). For this reason, we developed an Axis2-based webservice to act as a middleman between the BLIMS frontend and caTissue, abstracting away much of the internals of caTissue as well as performing custom SQL to process data faster than the regular API was able to.
BLIMS/SampleTrust is owned by Deloitte and UMass.
The application was written in the Java/Groovy-based Grails framework, and was designed to resemble a Windows desktop with a set of different tools available to technicians, a requirement that provided unique user interface challenges. These included facilities for searching for specimens by various properties, for entering layouts of physical tube racks (with the requirement that the form had to elegantly cope with the input from a handheld barcode scanner) and for recording procedures performed on tubes such as freezing, thawing and aliquotting. Data from lab equipment was also captured from files through Apache Camel.
The system had to interact with the open source biobanking system caTissue, which presented further challenges as at the time its developer API was inadequate to cover the needs of the project (being generally awkward to use and very slow at tasks like creating multiple samples at one time - a vital feature when the workflow involved separating samples into 96-well plates). For this reason, we developed an Axis2-based webservice to act as a middleman between the BLIMS frontend and caTissue, abstracting away much of the internals of caTissue as well as performing custom SQL to process data faster than the regular API was able to.
BLIMS/SampleTrust is owned by Deloitte and UMass.
Wrycan XMS
The Wrycan XMS (XML Management System) is a content management system for keeping track of XML documents as they pass through an editorial workflow, regularly being published through XSL templates to a site. While working for Wrycan, I was responsible for the development and maintenance of four branches of this system for various departments at Marathon Oil.
This involved working with an XML-based document workflow system (which was based on the now defunct OpenSymphony) and significant development work on the frontend in Java, JSP and JSTL. The most significant feature I worked on was the design and development of a system to allow users of the system to acknowledge changes to a document as part of the workflow - necessitating the design of an XML file format to store acknowledgement responses and communication with the client's SAP user database to verify staff codes.
The XML Management System is owned by Wrycan, Inc. - customizations were developed for Marathon Oil.
This involved working with an XML-based document workflow system (which was based on the now defunct OpenSymphony) and significant development work on the frontend in Java, JSP and JSTL. The most significant feature I worked on was the design and development of a system to allow users of the system to acknowledge changes to a document as part of the workflow - necessitating the design of an XML file format to store acknowledgement responses and communication with the client's SAP user database to verify staff codes.
The XML Management System is owned by Wrycan, Inc. - customizations were developed for Marathon Oil.
